Production-Grade RAG has quickly evolved from a research concept to a production standard for enterprise AI systems. While early tutorials often demonstrate RAG with a small document set and a simple vector search, real-world deployments demand far more sophistication. Production-grade RAG must manage scale, latency, data freshness, security, evaluation rigor, and multi-modal complexity, all while minimizing hallucination and cost.
The original RAG framework proposed combining parametric models with external knowledge retrieval to improve factual accuracy. Today, that idea underpins enterprise AI assistants, internal knowledge bots, compliance tools, and decision-support systems across industries. According to the 2024 McKinsey State of AI report, organizations deploying generative AI increasingly rely on retrieval-based approaches to reduce hallucinations and ensure policy alignment.
However, moving from proof-of-concept to production requires advanced architectural patterns. At Creative Bits AI, we treat RAG as a system engineering discipline, not a prompt hack.
This article explores advanced RAG strategies that go far beyond the basic tutorial.
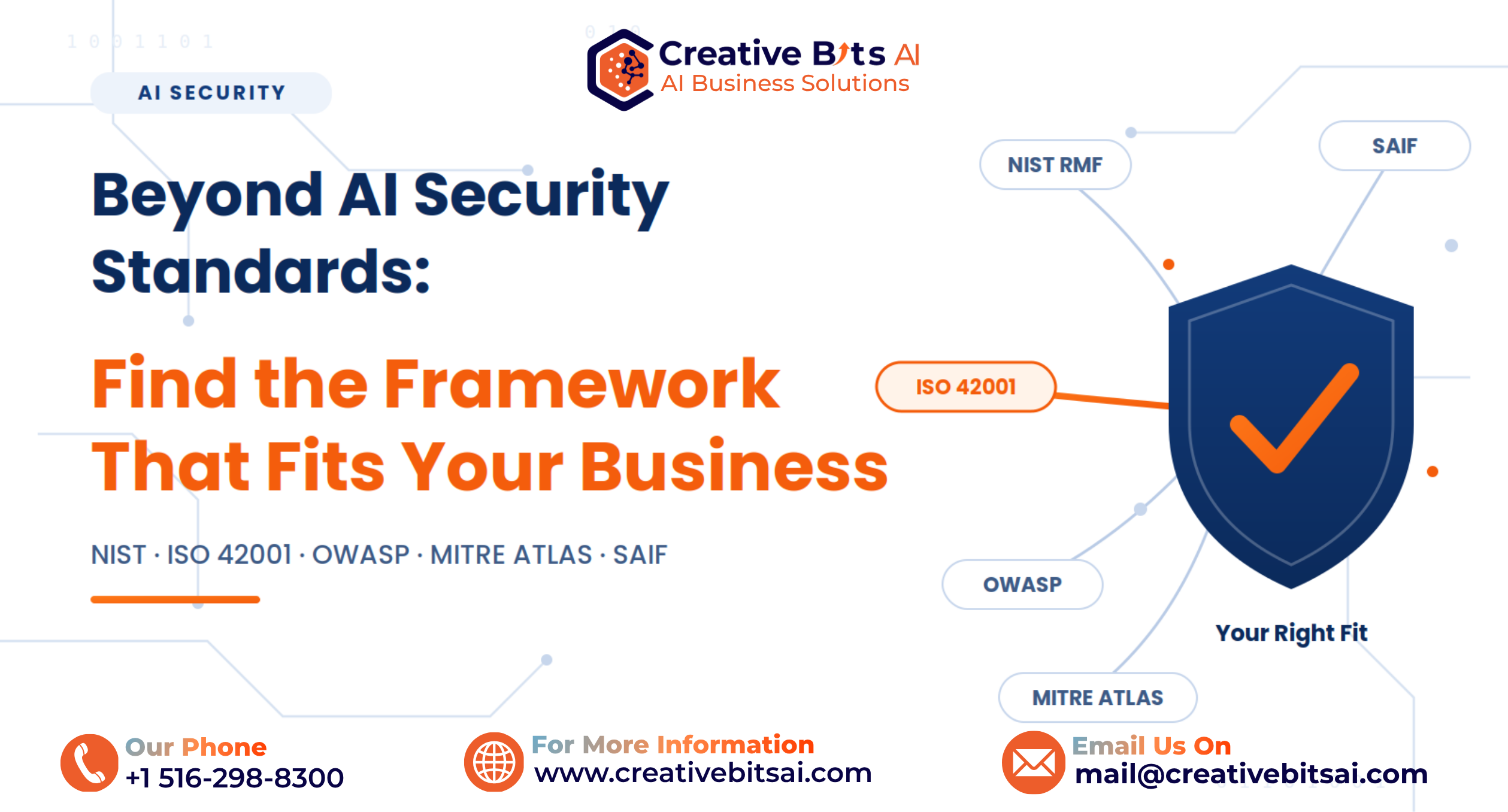
1. Hybrid Search Strategies: Moving Beyond Pure Vector Similarity
Most beginner RAG systems rely solely on dense vector search using embedding similarity. While vector databases such as Pinecone and Weaviate enable scalable semantic retrieval, production systems benefit from hybrid search that combines dense and sparse techniques.
Hybrid search blends traditional keyword-based retrieval (e.g., BM25) with semantic embeddings. Pinecone explicitly documents hybrid search capabilities that combine vector and sparse signals to improve relevance scoring. This approach mitigates a major weakness of pure embedding search: failure to capture exact term importance in structured domains such as legal, finance, or healthcare.
Similarly, Elastic’s hybrid search documentation shows how lexical search can be fused with vector similarity to improve retrieval precision. In enterprise contexts, keyword precision often matters as much as semantic similarity.
In production RAG, hybrid retrieval reduces both false positives and missed critical terms. Instead of retrieving documents purely by semantic closeness, systems weigh both contextual meaning and exact phrase matching.
At Creative Bits AI, we frequently implement weighted retrieval models where lexical signals protect high-risk compliance keywords while vector similarity handles broader context matching. The result is both precision and depth.
2. Reranking Mechanisms: Improving Retrieval Quality Before Generation
Even with hybrid search, initial retrieval often returns more documents than optimal. Production RAG systems, therefore, introduce reranking layers to refine results before passing context to the language model.
Reranking models evaluate retrieved passages and reorder them based on relevance to the user query. This is critical because LLM context windows are limited and expensive. Feeding irrelevant chunks increases cost and degrades answer quality.
Cohere provides documentation on reranking APIs designed specifically for improving RAG systems. Their rerank models score candidate documents based on query-document alignment, improving final response grounding.
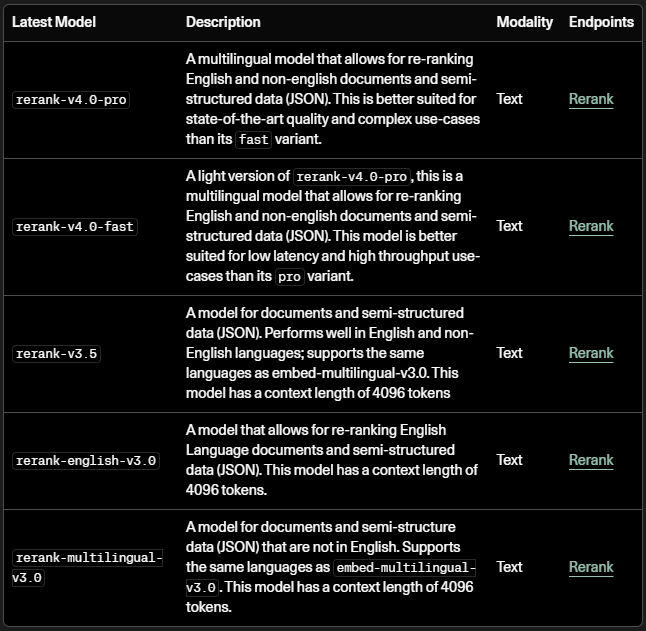
Academic research also reinforces the importance of reranking. The Hugging Face documentation on RAG pipelines emphasizes that two-stage retrieval—retrieve first, then rerank—consistently outperforms single-stage retrieval in question-answering benchmarks.
In enterprise systems, reranking significantly reduces hallucination risk. By ensuring that only the most relevant passages reach the generator, you improve both accuracy and confidence.
At Creative Bits AI, reranking is a default production layer. We treat retrieval as probabilistic and assume refinement is required before generation.
3. Chunk Optimization: Engineering Knowledge for Machine Consumption
One of the most overlooked aspects of RAG production is the chunking strategy. Poor chunk design is one of the primary causes of retrieval inefficiency and hallucination.
Chunk size determines recall quality. Too small, and semantic coherence breaks. Too large, and the retrieval precision drops. OpenAI’s documentation on embeddings emphasizes that preprocessing and chunk structuring significantly impact retrieval performance.
LangChain’s advanced RAG documentation further highlights recursive character splitting and context-aware chunking techniques. These strategies preserve semantic boundaries such as headings and paragraphs.
Production systems also use metadata enrichment. Adding document type, department tag, date, or version control metadata enhances filtering before retrieval. According to Weaviate’s vector database documentation, metadata filters combined with vector search drastically improve enterprise RAG reliability.
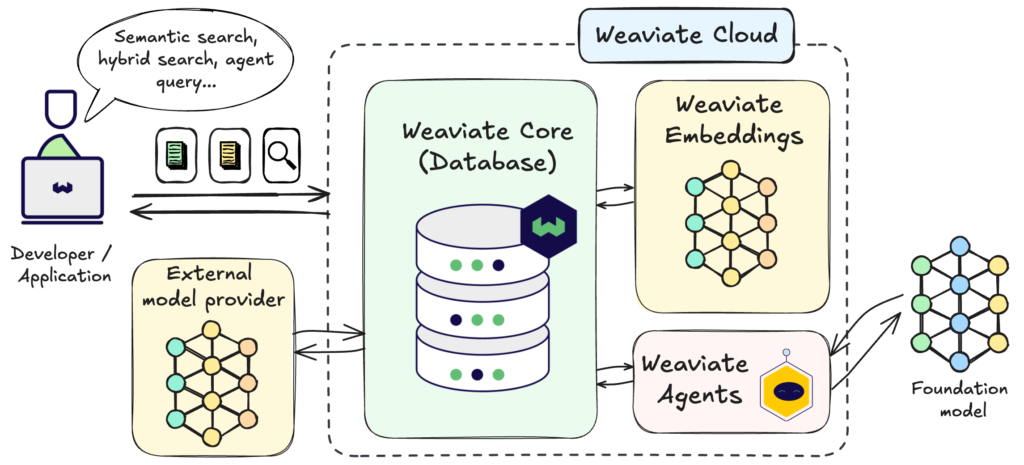
Another advanced pattern is dynamic chunk assembly. Instead of storing static chunks, some systems reconstruct context dynamically based on query patterns, merging adjacent sections when necessary. This reduces context fragmentation.
At Creative Bits AI, chunking is not an afterthought, it is a deliberate engineering decision. Knowledge must be structured for machines, not just humans.
4. Multi-Modal Enterprise Knowledge and System Governance
Modern enterprises do not operate solely on text. Knowledge lives in PDFs, spreadsheets, images, presentations, audio transcripts, and structured databases. Production RAG systems must handle multi-modal retrieval.
Google’s Gemini documentation describes multi-modal understanding capabilities across text, image, and document formats. Similarly, OpenAI’s GPT-4o model supports multi-modal inputs.
Multi-modal RAG pipelines require pre-processing layers that extract structured text from PDFs, perform OCR on images, and convert tabular data into structured embeddings. The challenge is not simply embedding everything, it is preserving context alignment across modalities.
Governance is equally critical. IBM’s 2024 AI governance insights emphasize the need for traceability and auditability in enterprise AI systems. Production RAG must log retrieval sources, track prompt versions, and maintain decision transparency.
Without governance, RAG systems may retrieve outdated or restricted information. Version-aware retrieval and access control layers prevent unauthorized exposure.
At Creative Bits AI, we design RAG systems with built-in observability: retrieval logs, citation tracking, confidence scoring, and policy enforcement. Production AI must be explainable, secure, and reversible.
RAG as Infrastructure, Not a Feature
Production-Grade RAG goes far beyond basic tutorials that show how to connect embeddings to a language model. Production RAG requires far more: hybrid search strategies, reranking layers, chunk optimization, metadata governance, multi-modal ingestion, and enterprise-grade monitoring.
The difference between a demo and a dependable system lies in the engineering discipline. Retrieval is probabilistic. Generation is non-deterministic. Production requires layered control.
At Creative Bits AI, we build RAG architectures that scale across departments, handle multi-modal enterprise knowledge, and maintain observability from query to response. Whether you are deploying an internal knowledge assistant, compliance intelligence system, or customer-facing AI tool, we engineer retrieval systems that are reliable, secure, and cost-aware.
If you’re ready to move beyond tutorial-grade RAG and build production-grade AI knowledge systems, connect with us at Creative Bits AI. Let’s transform retrieval into a strategic advantage.